DeepSeek-R1 알아보기

안녕하세요, 이번 포스팅에서는 DeepSeek에서 공개한 reasoning model, DeepSeek-R1의 기술 문서를 살펴보면서 과연 DeepSeek-R1은 어떤 모델인지 알아보는 시간을 가져보겠습니다.
중국의 기업 DeepSeek은 최근 값싸고 좋은 성능의 DeepSeek-V3 모델을 공개하여 LLM계의 강자로 급부상하고 있는데요, 2025년 1월 20일 DeepSeek-R1이라는 오픈소스 추론 모델을 공개하여 또 한번 주목을 받고 있습니다. 자체 벤치마크에 따르면, OpenAI-o1에 준하는 혹은 그 이상의 성능을 보인다고 하고, 특히 모델 개발 과정을 비교적 상세히 기술한 문서를 함께 공개하고 있어 오픈소스 LLM 연구에 많은 영감을 줄 것으로 기대가 됩니다. "Open-AI"를 OpenAI보다 더 몸소 실천하고 있는 게 DeepSeek이라는 것이 아이러니하네요. 😅 그럼 지금부터 DeepSeek-R1 기술 문서를 상세히 파헤쳐보도록 하겠습니다.
요약
- DeepSeek-R1-Zero와 DeepSeek-R1이라는 두 종류의 reasoning model을 오픈소스로 공개했습니다. 두 모델 모두 DeepSeek-V3-Base 모델 기반으로 reasoning을 위한 추가 학습을 진행하여 얻은 모델입니다.
- DeepSeek-R1-Zero는 supervised fine-tuning (SFT) 없이, 오로지 large-scale reinforcement learning (RL)로만 학습되었음에도 불구하고 훌륭한 reasoning 성능을 보여줍니다. 다만, 결과물의 가독성이 떨어지고 출력 언어가 뒤섞여서 나타난다는 단점이 있습니다.
- 이러한 문제를 해결하기 위해 정제된 cold-start 데이터를 사용하고, multi-stage 학습을 수행하여 DeepSeek-R1 모델을 얻습니다.
- DeepSeek-R1 모델은 reasoning task들에서 OpenAI-o1-1217에 준하는 성능을 보여줍니다.
- 위의 두 모델과 더불어, DeepSeek-R1 기반의 distilled model 6종 (1.5B, 7B, 8B, 14B, 32B, 70B)을 공개했습니다. 이 모델들은 Qwen과 Llama 기반으로 학습되었습니다.
들어가며
최신 LLM 개발 동향을 살펴보면 post-training이 pre-training 만큼이나 중요한 요소로 떠오르고 있습니다. 잘 학습된 pre-trained LLM을 가지고, 어떤 방식으로 후속 학습을 수행하느냐에 따라서 reasoning 성능이 향상되기도 하고, 사회적인 가치에 부합하는 모델이나 개인 맞춤형 모델을 만들어낼 수도 있죠. 이 작업들을 pre-training에 비해 매우 적은 비용으로 수행할 수 있다보니 이 post-training에 많은 연구들이 이루어지고 있는 추세입니다.
Reasoning 성능 면에서 살펴보자면, OpenAI o1 계열 모델들은 inference-time에 명시적으로 chain-of-thought 과정의 길이를 늘임으로써 수학 및 과학 문제 해결, 코딩 등의 reasoning task들에서 좋은 성능을 보일 수 있었던 것으로 보입니다. 다만 o1 역히 여타 OpenAI 모델들과 같이 그 학습 과정을 쉽게 알 수 없는데요, OpenAI의 공식 문서에 따르면, o1 학습에는 large-scale RL이 사용되었으며, "데이터 효율성이 좋은(data-efficient)" 학습이 이루어졌다는 정도만을 힌트로 얻을 수 있을 뿐이었습니다. 잘 labeling된 chain-of-thought 데이터가 아니어도 학습에 사용할 수 있었다는 의미로 추측해볼 수 있겠습니다.
DeepSeek-R1 또한 여기서 영감을 얻었을지는 모르겠지만, 순수하게 RL 기반으로 reasoning 학습을 수행하는 것을 목표로 합니다. 마치 AlphaZero가 사람이 만든 바둑 기보 없이도 바둑을 마스터할 수 있었던 것처럼, reasoning과 관련된 label (chain-of-thought annotation) 없이도 모델이 RL 프레임워크 안에서 스스로 reasoning하는 법을 배울 수 있는지를 알아보고자 하는 것이죠.
DeepSeek-R1-Zero
RL을 이용하여 reasoning 학습이 가능한지 알아보기 위해, DeepSeek-R1-Zero는 supervised fine-tuning (SFT)에 의존하지 않고, 오로지 RL만을 이용하여 chain-of-thought 경로를 탐색할 수 있도록 학습되었습니다.
RL 알고리즘
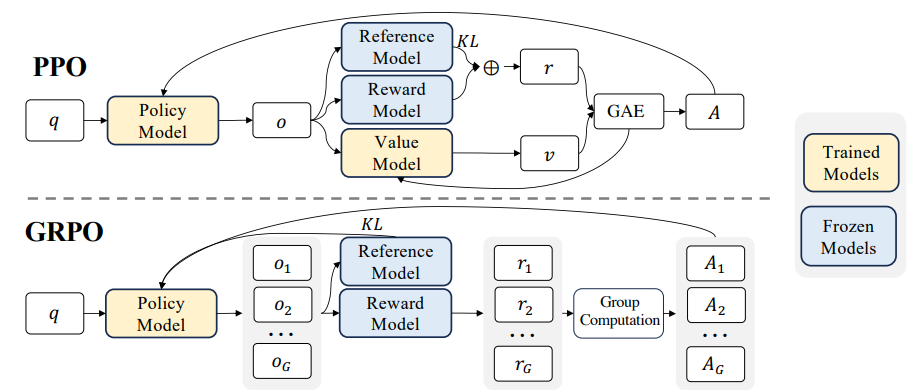
DeepSeek-R1-Zero는 RL 학습에 Group Relative Policy Optimization (GRPO)를 사용합니다. 이는 DeepSeekMath 논문에서 제안된 방법으로서, 이전까지 RL을 이용한 LLM fine-tuning에 주로 사용되어왔던 Proximal Policy Optimization (PPO)와는 달리 value model을 두지 않고, 같은 입력에 대한 여러 sampled output의 reward 값의 평균을 baseline으로 대신 사용하여 더 효율적인 학습이 가능하게 하는 방법입니다. 더 자세한 내용은 DeepSeekMath 논문을 참고해주세요!
Reward 정의
모델의 출력값을 평가하는 척도인 reward 정의는 RL 학습에 있어 꼭 필요합니다. DeepSeek-R1-Zero에서는 아래와 같이 매우 간단한 rule-based reward 정의를 이용합니다.
- 정확도 (accuracy reward) : 마치 바둑에서 최종 승리에 reward를 부여하는 것처럼 reasoning 결과로 모델이 내놓은 결과가 정답일 때 reward를 부여합니다.
- 출력 형식 (format reward) : 학습 시에, 모델은 사고 과정을 <think> 와 </think> 태그 사이에 넣도록 출력 형식이 주어집니다 (아래 참조). 이 출력 형식을 맞추었는지에 대한 reward가 되겠습니다.
학습 프롬프트 템플릿

prompt 부분에 학습에 사용하는 reasoning question이 삽입된다.모델이 입력 프롬프트에서 힌트를 얻어서 reasoning 경로를 구성하지 않고, 오직 RL 학습 프레임워크 상에서 reasoning이 학습되도록 강제하기 위해서 DeepSeek-R1-Zero 학습에는 위와 같은 정해진 형식의 프롬프트 템플릿이 사용됩니다.
학습에 따른 성능 향상 추이
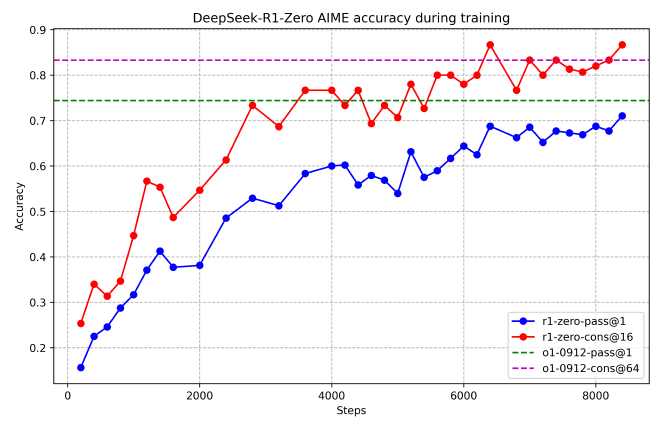
학습이 진행됨에 따라, reasoning task에서 굉장히 큰 폭으로 성능이 향상됨을 확인할 수 있습니다. AIME 2024에서의 pass@1 (1번의 도전으로 정답을 맞춘 비율) 점수가 15.6%에서 71.0%로 껑충 뛰어올랐네요. 이는 OpenAI-o1-0912의 성능과 유사한 수준입니다. RL 학습이 잘 작동함을 알 수 있습니다.
추가적으로, 다수결(majority voting) 전략을 사용 시 성능이 더 향상될 수 있음을 보여줍니다. 16번 도전한 다음, 가장 많이 정답으로 제시된 값을 정답으로 삼는 거죠. 일종의 앙상블이라 보면 되겠습니다. 이 경우, DeepSeek-R1-Zero의 성능은 71.0%에서 86.7%로 더욱 향상되어 OpenAI-o1-0912의 성능을 뛰어넘는 결과를 보여주네요.
모델의 사고 과정의 자가진화 (self-evolution)
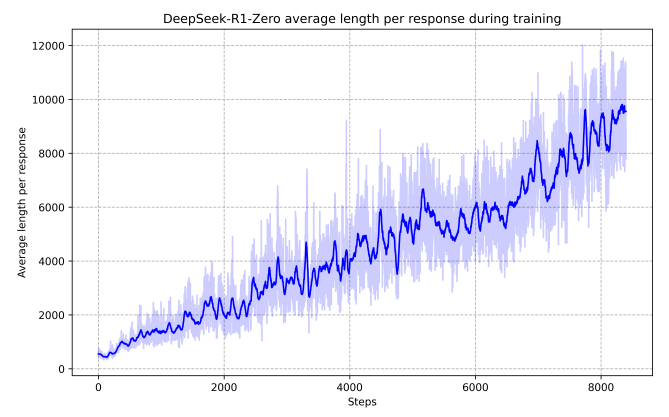
다음으로 학습 과정에서 모델의 reasoning이 어떻게 변화하는지 확인해보았습니다. 재미있게도, 학습이 진행됨에 따라서 모델의 chain-of-thought 과정은 일관되게 증가합니다. 즉, 정답을 맞추기 위해서는 더 많은 사고 과정을 거쳐야 함을 배우고 있다는 것이겠죠! 이 학습 과정이, "사고 과정" 자체를 label로 제공한 supervised fine-tuning이 아닌, 문제와 정답만을 제공하고 자유로운 사고 과정을 허용한 RL 프레임워크 하에서 이루어졌다는 것을 생각하면, 놀라운 결과라고 생각이 드네요.
모델의 사고 과정을 자세히 들여다보면 더욱 놀랍습니다. 더 많은 test-time computation을 허용할수록 이전의 사고 과정을 검토하는(reflection) 등의 행동이 관찰되기 시작한다고 하는데요, 모델에게 어떠한 가이드도 주지 않았음에도 이러한 사고 패턴을 학습할 수 있었다는 점이 굉장히 흥미롭습니다.
깨달음의 순간 (Aha-moment)

사고 과정의 진화를 보여주는 단적인 예시로, 모델이 스스로 무언가를 깨우치는 "aha-moment"를 사고 과정 도중 만나는 것을 확인했다고 합니다. 이 무렵에는 모델이 자신의 초기 해결책을 다시 검토하는 데 시간을 많이 할애한다고 하네요.
저자들도 이 Aha-moment가 마음에 들었는지, 약간은 감상적인 투로 자신들의 느낌을 전하고 있습니다.
이 순간은 단지 모델 뿐 아니라 이를 관찰하는 연구자들에게도 깨달음의 순간으로 다가옵니다. 이는 강화학습의 힘과 아름다움을 보여줍니다: 문제를 푸는 방법을 하나하나 가르치지 않았음에도, 적절한 보상만을 주었더니 스스로 문제를 해결하는 전략을 세우는 법을 학습한 것이죠. 이 "aha-moment"는, 문턱을 넘어 새로운 수준의 인공지능을 만들어내는 도구로써 강화학습의 잠재력을 보여주는 매우 확실한 단서입니다.
DeepSeek-R1-Zero의 단점
Reasoning 학습에 있어 RL 프레임워크의 효과를 충분히 확인했지만, 실제 사용에 있어 DeepSeek-R1-Zero는 아래와 같은 단점이 있다고 합니다.
- 낮은 가독성
- 여러 언어들이 섞인 출력 결과
DeepSeek-R1
DeepSeek-R1-Zero의 유망한 결과를 보면, 아래를 생각해볼 수 있습니다.
- DeepSeek-R1-Zero에서는 학습 시작 시 전체 학습의 방향을 가이드하거나 가속화할 수 있는 cold-start 데이터를 사용하지 않았습니다. 질 좋은, 적은 양의 cold-start 데이터를 활용해서 모델 학습을 시작한다면 성능이 더 좋아지거나 수렴이 빨라질까요?
- 서비스 측면에서, reasoning 성능은 물론 중요하지만 그만큼 중요한 것은 사용자에게 얼마나 투명한 결과를 보여주느냐입니다. Chain-of-thought 경로를 잘 구성해서 보여주는 모델이나, general capability가 좋은 모델을 만들 수 있을까요?
Cold-start 데이터
DeepSeek-R1-Zero와는 달리 DeepSeek-R1 학습의 극초반에는 적은 수의 long-CoT 데이터를 사용합니다. DeepSeek-R1-Zero에서는 모델이 무모한 시행착오를 거쳐야 해서 초반 학습이 불안정했다면, DeepSeek-R1의 경우 이 long-CoT가 일종의 "좋은 policy를 보여주는" RL actor로서 기능하여 fine-tuning을 안정화시키기를 기대해볼 수 있겠습니다.
아래 방법을 사용하여 수천 개 정도의 cold-start 데이터를 사용했다고 합니다.
- Long-CoT를 예시로 준 few-shot prompting을 통해 얻은 출력
- 결과 검토(reflection)와 확인(verification)을 강제하는 프롬프트를 사용한 출력
- DeepSeek-R1-Zero 출력
- Human annotator가 직접 수정한 결과
이렇게 cold-start 데이터를 사용하는 이점은 아래와 같습니다.
- 가독성 (Readability): DeepSeek-R1-Zero의 출력은 여러 나라의 언어가 섞여 있고, 마크다운 포맷으로 구성되어 있지 않아서 사용자 친화적이지 않습니다. (당연히 정답만 맞추면 되니까 이런 식으로 학습되었겠죠?). 반면 DeepSeek-R1의 cold-start 데이터는 잘 정제된 데이터만 사용하여 모든 답변의 끝부분에는 사고 과정의 요약이 담겨 있도록 구성했다고 합니다. 이렇게요:
|special_token| <reasoning_process> |special_token| <summary> - 성능 잠재력 (Potential): 인간의 사고 과정을 모방하도록 cold-start 데이터를 구성한 결과, DeepSeek-R1-Zero보다 더 좋은 성능을 보였다고 합니다.
Reasoning-oriented Reinforcement Learning
이렇게 cold-start 데이터를 사용한 fine-tuning이 끝나고 나면, DeepSeek-R1-Zero와 같은 방식의 RL 학습이 진행됩니다. 이 과정에서는 코딩, 수학, 과학, 논리추론 등 정답이 확실히 정해져 있고, 복잡한 사고 과정을 거쳐야 하는 데이터들을 주로 활용했다고 합니다.
Cold-start 데이터를 활용했지만 여전히 CoT 상에 여러 언어가 섞여 나타나는 현상이 가끔 발생했다고 합니다. 이를 완화하기 위해, 목표 언어가 CoT에 얼마나 많은 비중으로 나타나는지를 계산한 "언어 일관성" reward를 추가하였다고 합니다. 이 reward의 사용으로 인해서 약간의 성능 하락이 있기는 했지만, 서비스적인 측면에서는 꼭 필요한 작업이라 볼 수 있겠습니다.
Rejection sampling을 통한 SFT 학습 데이터 생성
Reasoning-oriented RL 단계가 끝나게 되면, 다음 학습 round인 Supervised fine-tuning을 위한 데이터를 현재까지 학습된 파라미터로부터 만들어냅니다. Supervised fine-tuning을 위해서는 질 좋은 (CoT, 정답) 데이터가 필요한데, 이를 위해서 rejection sampling 전략을 취합니다. 쉽게 말해, 일단 모델로 하여금 (CoT, 정답) 쌍을 생성하게 하고, 이를 어떻게든 평가하여 질 나쁜 데이터는 제거하는 전략입니다. 아래와 같은 방식으로 걸러냅니다.
- Generative reward model : 이전까지는 단순히 rule-based reward만 사용했다면, 여기서는 DeepSeek-V3에게 (CoT, 모델이 예측한 정답, 진짜 정답) 쌍을 제공하여 데이터의 점수를 매기도록 합니다
- CoT filtering : 언어가 섞여 있는 경우, 문단이 너무 긴 경우, 코드 블럭이 포함된 경우 제거합니다. (CoT에 코드도 쓰나보네요)
- 정답 filtering : 프롬프트 하나 당 여러 (CoT, 정답) 쌍을 생성하고 그 중 진짜 정답을 맞춘 경우만 사용합니다.
이 과정을 거쳐 총 600,000개의 reasoning-related SFT 학습 셋을 꾸릴 수 있었습니다.
Non-reasoning 데이터
DeepSeek-R1은 reasoning 뿐 아니라, 범용적으로도 활용 가능하게 학습하고 싶었다고 합니다. 이를 위해 DeepSeek-V3 학습 시 사용했던 데이터 처리 파이프라인과 DeepSeek-V3 학습 SFT 데이터 일부를 사용했다고 하네요. 이를 통해 총 200,000개의 non-reasoning 셋을 꾸렸습니다.
이렇게 모은 총 800,000개의 데이터를 2 epoch동안 학습하여 SFT 과정을 진행하게 됩니다.
Human preference를 반영한 2차 RL 학습 (Safety RL)
Reasoning capability를 더 향상시키고, 동시에 모델의 helpfulness와 harmlessness를 확보하기 위해 끝으로 한 번 더 Safety RL 학습을 진행하게 됩니다. Reasoning 데이터의 경우 DeepSeek-R1-Zero 의 rule-based reward를 똑같이 사용하며, general 데이터의 경우에는 human preference에 더 맞는 방향으로 reward를 설정하여 학습을 진행합니다.
Distillation
지금까지 DeepSeek-R1-Zero와 DeepSeek-R1 모델의 학습 방식에 대해 알아보았습니다. 끝으로, DeepSeek-R1 모델의 distillation을 통해 훨씬 크기가 작은 Qwen, Llama 모델들의 reasoning 성능이 얼마나 향상될 수 있었을지 알아봅시다.
DeepSeek-R1의 SFT phase에 사용했던 800,000개 데이터를 기억하시나요? DeepSeek-R1 모델의 distillation 과정에는 이 데이터를 활용합니다. 기반 모델은 아래의 6개 모델이 되겠습니다.
- Qwen2.5-Math-1.5B
- Qwen2.5-Math-7B
- Qwen2.5-14B
- Qwen2.5-32B
- Llama-3.1-8B
- Llama-3.3-70B-Instruct
참고로 distillation 시에는 SFT만 사용하고, RL은 사용하지 않았다고 합니다. 이 분석의 목적은 RL로 reasoning을 학습한 모델의 distillation이 얼마나 효과적인지 알아보기 위함이니까요!
벤치마크
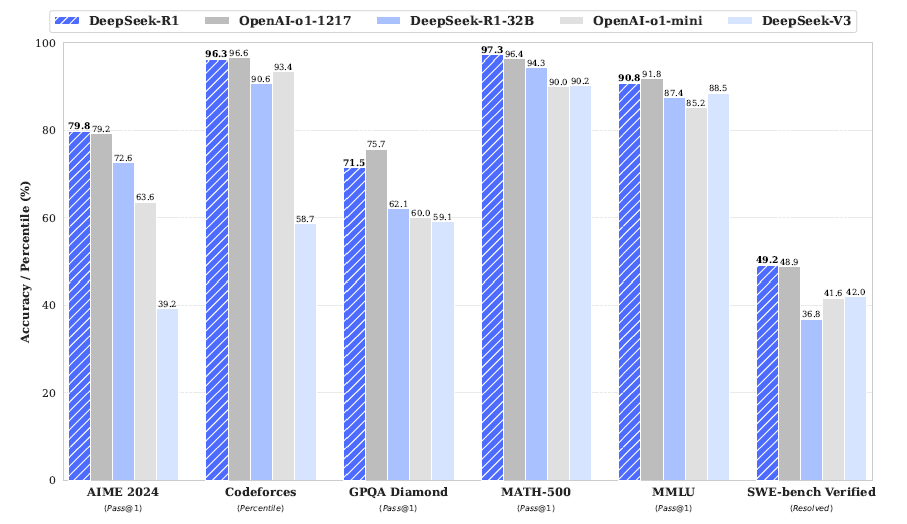
DeepSeek-R1 벤치마크
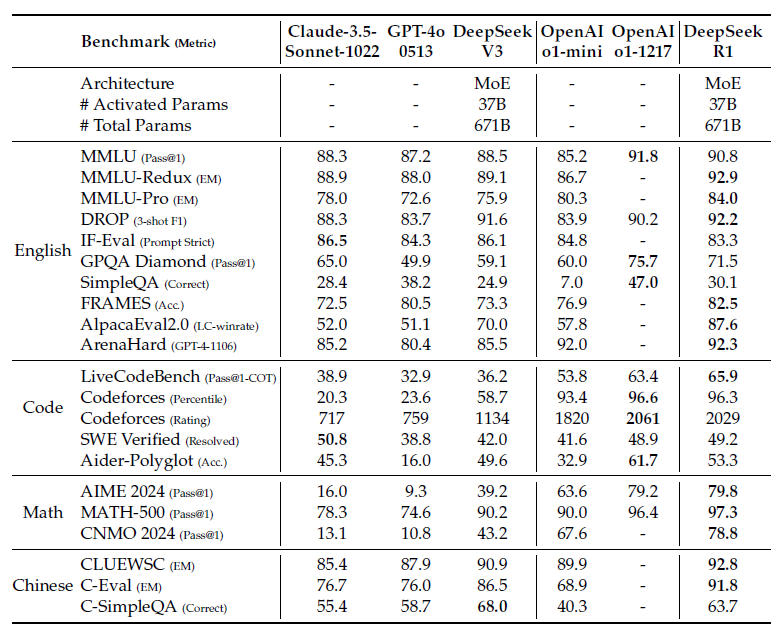
DeepSeek-R1 모델의 성능 벤치마크는 간단히만 요약으로 짚고 넘어가겠습니다.
- MMLU, MMLU-PRo, GPQA Diamond와 같은 지식 벤치마크에서는 DeepSeek-V3를 능가하는 성능을 보였습니다.
- Long-context-dependent QA 벤치마크인 FRAMES 벤치마크에서 훌륭한 성능을 보였습니다. 문서를 읽고, 서로 멀리 떨어진 지식 간의 관계를 잘 연결한다는 의미입니다.
- SimpleQA와 같은 언어모델 사실성 벤치마크에서 DeepSeek-V3를 능가했습니다. Hallucination이 더 적거나, 쿼리와 학습된 지식 사이의 연결을 잘 찾는다는 것으로 볼 수 있겠습니다.
- 다만, Chinese SimpleQA 벤치마크에서는 오히려 DeepSeek-V3보다 낮은 성능을 보였는데, 이는 Safety RL 학습 때문에 특정 query에 대한 응답을 거부했기 때문이라고 합니다. Safety RL 학습이 없으면 >70% 성능이 나온다고 하네요.
- Format instruction을 얼마나 잘 따르는지 보는 벤치마크인 IF-Eval에서 좋은 성능을 보였다고 하는데, 테이블에는 DeepSeek-V3보다 하락한 수치입니다. 기재 오류일까요?
- 수학 문제 해결 task에서는 OpenAI-o1-1217과 유사한 성능을 보였습니다. 코딩 벤치마크에서도 마찬가지네요.
- 소프트웨어 공학 관련 벤치마크 Aider-Polyglot 에서는 OpenAI-o1-1217보다는 약간 떨어지는 성능을 보였습니다. SWE verified에서는 비슷한 성능입니다.
Distilled model 벤치마크
6종의 distilled 모델의 성능은 어땠을까요? DeepSeek-R1의 힘을 잘 물려받아서 reasoning task를 잘 해결할 수 있었을까요?
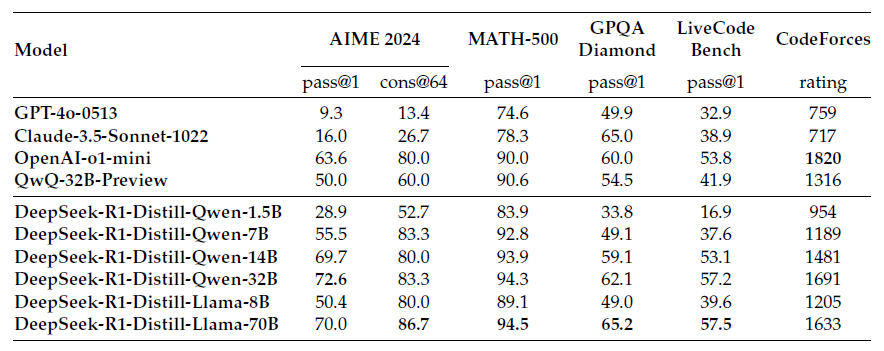
- DeepSeek-R1의 출력을 distill했을 뿐인데, DeepSeek-R1-Distill-Qwen-7B 모델이 무려 GPT-4o-0513 모델을 능가하는 모습입니다. Reasoning 모델과 non-reasoning 모델의 극명한 차이를 보여주네요.
- DeepSeek-R1-Distill-Qwen-14B는 QwQ-32B-Preview를 능가합니다.
- DeepSeek-R1-Distill-Qwen-32B와 DeepSeek-R1-Distill-Llama-70B는 o1-mini를 능가합니다.
- 이 Distilled 모델에 추가적인 RL 학습을 수행하면, 성능이 더 향상된다고 합니다! (보여진 결과는 없음)
Distillation vs RL
DeepSeek-R1이 만들어준 800,000개 reasoning 학습 데이터의 힘을 확인할 수 있습니다. 그렇다면, reasoning 학습에 이 800k 데이터를 활용하여 SFT를 수행하는 것과, DeepSeek-R1-Zero처럼 RL을 수행하는 것 중 어떤 것이 더 좋을까요?

위는 Qwen-32B 모델을 RL 학습한 DeepSeek-R1-Zero-Qwen-32B 모델과, DeepSeek-R1 모델이 생성한 reasoning 데이터로 distillation된 DeepSeek-R1-Distill-Qwen-32B 모델의 성능을 비교한 결과입니다. RL 학습으로도 QwQ-32B-Preview와 유사한 reasoning 성능을 달성할수는 있지만, distillation에 비해서는 효과적이지 못한 모습이네요.
아래와 같은 두 가지 결론을 내릴 수 있겠습니다.
- 큰 모델을 작은 모델로 distillation하는 것은 매우 효과적이고, 심지어 작은 모델을 large-scale RL 학습하는 것으로는 달성할 수 없는 지점까지 성능을 끌어올려줄 수 있다.
- 반대로 말하면, distillation은 분명 경제적이고 효과적인 학습 전략이긴 하지만, 어찌됐든 이 distillation을 위한 큰 모델의 학습은 궁극적으로는 꼭 필요하다.
결론
오늘은 DeepSeek-R1 기술 문서를 살펴보면서, 어떤 식으로 LLM에 reasoning 능력을 부여할 수 있는지 알아보는 시간을 가져보았습니다. 아주 간단한 RL reward와 좋은 학습 전략이 있을 때, 모델이 "사고하는 방법" 자체를 점차적으로 배워나가는 현상이 발생한다는 것을 확인할 수 있었습니다. 개인적으로는 그 과정의 chain-of-thought이 다양한 언어 (심지어 코드로도!) 로 나타난다는 단점도 오히려 긍정적으로 해석이 되더라구요. 언어의 제약조건이 없어서 그렇지, 출력 언어로 표상된 것의 기저에 깔린 사고 과정에 집중하여 모델이 학습하고 있다는 방증이 아닐까 싶습니다.
DeepSeek-R1-Zero, DeepSeek-R1 및 6종의 distillation 모델이 오픈소스로 공개되었기 때문에 이 reasoning 모델을 바탕으로 하여 또 어떤 방식으로 LLM 연구/개발의 트렌드가 바뀌어갈지 귀추가 주목되네요. 읽어주셔서 감사합니다!

![[Python] trafilatura 라이브러리로 크롤링 쉽게 하기](https://images.unsplash.com/photo-1470334165954-365e14d84faa?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fHBlbGljYW5zJTIwfGVufDB8fHx8MTczNzE4MDg0MXww&ixlib=rb-4.0.3&q=80&w=960)

![[shell] 문자열 변수에서 고정된 prefix / suffix 잘라내기](https://images.unsplash.com/photo-1596518432939-479596b448b3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDM1fHxzY2lzc29yfGVufDB8fHx8MTczNjY5Mzk1NXww&ixlib=rb-4.0.3&q=80&w=960)