인공지능 LLM 모델 수능 성적 비교하기 - 영어 편 (1)
직접 해봤습니다. GPT, Claude, DeepSeek-V3와 같은 유료 모델부터 Phi-4, Qwen2.5와 같은 오픈소스 모델까지, 여러 AI 모델들의 성능을 한꺼번에 비교하는 벤치마크를 수능 문제들을 활용하여 한 번 스스로 만들어 봅니다.

하루가 멀다하고 새로운 LLM 모델들이 만들어져 배포되고 있는 요즘입니다. 일반적으로는 OpenAI의 GPT-4o-mini 혹은 Anthropic의 Claude-3.5-sonnet, 혹은 최신의 DeepSeek-V3와 같은 모델을 약간의 돈을 지불하고 사용하는 것이 최선의 선택일텐데요. (DeepSeek-V3는 오픈소스지만.. 671B 모델을 개인적으로 서빙할 수는 없기에 사실상 유료입니다) 개발자라면 어떤 모델이 더 좋은지, 직접 벤치마크 해보고 싶은 것이 당연합니다. 그래서 해봤습니다. GPT, Claude, DeepSeek-V3와 같은 유료 모델부터 Phi-4, Qwen2.5와 같은 오픈소스 모델까지, 여러 AI 모델들의 성능을 한꺼번에 비교하는 벤치마크를 수능 문제들을 활용하여 한 번 스스로 만들어 볼 겁니다.
수능을 치르게 하자
옛날 챗봇 인공지능의 목표는 문법적으로/언어적으로 자연스러운 대답이었습니다. 하지만 ChatGPT를 위시한 LLM의 등장 이후로, 어느 정도 완성도 있는 모델이라면 알맹이가 없는 말을 할 수는 있어도, 언어적으로 부자연스러운 대답을 내놓는 경우는 거의 없죠. 사용자 입장에서도 모델이 사람처럼 자연스러운 형태로 문장을 구성하여 답변을 내놓는 것은 더이상 놀랍지 않습니다. 단순한 말동무나 질의 응답 도구를 넘어, 이제 우리는 AI 모델에게 복잡한 논리적 추론을 기대하기 시작한 겁니다. Chain-of-thought 프롬프팅을 시작으로 최근의 OpenAI-o1 모델까지, LLM 모델의 추론 능력은 기하급수적으로 빠르게 발전하고 있습니다. 이런 모델의 논리적 사고력은 어떻게 벤치마크 해볼 수 있을까요?
업계에서는 수학문제를 풀게 한다거나, 코딩을 시켜본다거나 하는 다양한 벤치마크들을 사용하여 자신들이 만든 모델의 우수성을 뽐내곤 하는데요, 여기서는 그 대신 수능 문제를 한 번 풀게 해보면 재밌을 것 같습니다. 대한민국 학생 전체의 논리적 사고력을 평가하기 위해 면밀히 설계된 문제들이니까요 😏
 Marker-Inc-Korea
Marker-Inc-Korea위 GitHub을 둘러보시면 아시겠지만, 이미 GPT, Gemini, HyperClovaX 등등의 모델들로 수능 대결을 치른 결과는 알려져 있습니다. 현재까지의 결과는 o1-Preview가 영예의 1위를 차지하고 있네요. 또 수능 국어 1등급에 도전하는 AI를 만들기 위한 프로젝트를 만드신 분들도 있습니다. 재밌으니 꼭 확인해보시길 바랍니다.
하지만 이런 벤치마크는 직접 만들어서 돌려보는 것이 더 재밌잖아요? 내 손으로 만든 시스템에서 이것저것 바꿔보며 실험하기도 좋구요. 한번 바닥부터 스스로 만들어 봅시다.
영어부터
수능에는 다양한 과목이 있습니다. 국어, 영어, 수학, 과탐, 사탐 등등.. 이 중 코딩이 가장 간단할 것 같은 영어 과목부터 시작해 봅시다. 학습 데이터 중 한국어 데이터보다는 영어 데이터 비중이 훨씬 높을 테니, 성적도 더 잘 나올 것 같구요.
데이터 수집
데이터는 우선 2025학년도 수능 영어 문제 (홀수형) 데이터를 활용합니다. PDF 파일로 제공하는데요, PDF 파일을 잘 파싱해서 자동으로 문제를 뽑아낼 수 있을 것도 같지만.. 우선은 문제 수가 얼마 되지 않으니 수동으로 파싱해 봅시다.
듣기평가는?
과감히 생략합니다. Speech-to-text 모델을 써서 텍스트로 바꾼 다음 문제화시킬 수도 있을 것 같은데, 벤치마크 설계가 너무 복잡해질 것 같군요.
문제에 그림이나 그래프가 있는 문제는?
역시 과감히 생략합니다. Vision capability가 있는 모델을 사용하면 되지만, 여기서는 텍스트 기반 논리 추론 능력만 보고자 합니다.
데이터 구조화
각각의 문제를 하나의 yaml 파일로 구조화하면 재사용하기가 좋겠네요. 우선 디렉토리 구조는 아래와 같이 만들어 줍니다.
.
├── problems
│ └── 2025
│ └── eng
│ ├── 18.yaml각 문제 별로 프롬프트에는 문제, 제시문, 선지 이 3가지 요소를 넣어줄 것이고, 채점을 위해서 정답 값이 필요합니다. 18.yaml 파일을 한번 볼까요?
question: 다음 글의 목적으로 가장 적절한 것은?
text: |
Dear Rosydale City Marathon Racers,
We are really grateful to all of you who have signed up for
the 10th Rosydale City Marathon that was scheduled for
this coming Saturday at 10 a.m. Unfortunately, as you may
already know, the weather forecast says that there is going
to be a downpour throughout the race day. We truly hoped
that the race would go smoothly. However, it is likely that
the heavy rain will make the roads too slippery and
dangerous for the racers to run safely. As a result, we have
decided to cancel the race. We hope you understand and
we promise to hold another race in the near future.
Sincerely,
Martha Kingsley
Race Manager
choices:
- 마라톤 경기 취소 사실을 공지하려고
- 마라톤 경기 사전 행사 참여를 독려하려고
- 마라톤 경기 참가비 환불 절차를 설명하려고
- 마라톤 경기 참여 시 규칙 준수를 당부하려고
- 마라톤 경기 진행에 따른 도로 통제를 안내하려고
answer: 1이런 식으로, question (문제), text (제시문), choices (선지), answer (정답) 데이터를 구조화할 수 있습니다. 이제 이 작업을 모든 가능한 2025학년도 수능 영어 문제에 대해 반복해 주면, 총 27개의 문제를 얻습니다.
프롬프트
같은 모델이라도 어떻게 프롬프트를 작성하여 제공하느냐에 따라 성능이 꽤 많이 달라집니다. 이 벤치마크에서는 최대한 엔지니어링 없이, 단순한 프롬프팅을 사용해 보겠습니다. (나중에 프롬프트에 따라 어떻게 수능 성적이 달라지는지 확인해보는 것도 재밌겠네요!) 저는 개인적으로 XML 프롬프팅을 좋아하는데요, 내가 원하는 바를 구조화하면서 스스로도 문제 인식이 명확해지기도 하고, 작성하는 데 드는 노력에 비해 결과물이 좋다는 느낌이 들어서입니다. 이번에도 XML 프롬프팅을 사용하여 프롬프트를 작성해 보겠습니다. 아래와 같습니다.
<role>
You are a professional problem solver.
</role>
<task>
Given a question and a text, find the answer to the question.
</task>
<instructions>
<instruction>Think step by step.</instruction>
</instructions>
<rules>
<rule>You MUST return the answer in JSON format with two keys: "answer" (integer) and "reasoning" (string)</rule>
<rule>You MUST DISCARD ```json and ``` in the result</rule>
<rule>NEVER include meta-commentary or explanations in the result, just return the JSON</rule>
<rule>The key "answer" must be the index of the choice that is the answer (integer)</rule>
<rule>The key "reasoning" must be a short explanation for the answer (string)</rule>
</rules>
<question>
{question}
</question>
<text>
{text}
</text>
<choices>
<choice index="1">{choices[0]}</choice>
<choice index="2">{choices[1]}</choice>
<choice index="3">{choices[2]}</choice>
<choice index="4">{choices[3]}</choice>
<choice index="5">{choices[4]}</choice>
</choices>{question}, {text}, {choices[0]} 등과 같이 템플릿화 하고 있음을 알 수 있습니다. 여기서 팁이 하나 있습니다. Claude와 같은 플랫폼들은 prompt caching을 통해 반복적인 프롬프트 입력에 대해 보다 싼 가격에 빠른 답변을 제공하고 있다는 건데요, 주의할 점은, prompt의 앞부분(prefix) 일정 비율이 똑같아야 prompt caching이 작동한다는 점입니다. 즉, 변화하는 템플릿 부분은 뒤에 배치할 수록 유리하다는 거죠.
<instruction> 부분에는 유명한 "Think step-by-step" 프롬프트를 그냥 한 번 넣어봤습니다. 나중에 이 프롬프트가 과연 효과가 있었는지 실험해볼 수도 있겠네요 🤔
<rule> 부분에는 벤치마크 과정의 자동화를 위해 답변을 JSON 형식으로 반환하도록 하고, 답변과 그 근거를 반환하도록 했습니다. 찍어서 정답을 맞췄는지 보는 것도 재밌잖아요!
문제를 파싱하고, 프롬프트를 구성하는 모듈 (parser.py)의 전체 코드는 다음과 같습니다.
import yaml
def load_yaml(path):
with open(path, "r") as f:
return yaml.load(f, Loader=yaml.FullLoader)
def parse_problem(year, subject, problem_idx):
problem = load_yaml(f"problems/{year}/{subject}/{problem_idx}.yaml")
problem["text"] = problem["text"].replace("\n", " ")
problem["answer"] = int(problem["answer"])
return problem
def compose_prompt(year, subject, problem_idx):
problem = parse_problem(year, subject, problem_idx)
with open("prompts/english.txt", "r") as f:
prompt = f.read()
return prompt.format(question=problem["question"], text=problem["text"], choices=problem["choices"])모델 선정
어떤 모델들을 비교해볼지 고민이 많았는데요, 우선 이 벤치마크가 잘 작동하는지 확인하기 위한 목적으로, 값싼 모델들과 Ollama를 통해 무료로 돌려볼 수 있는 작은 모델들 위주로 벤치마크를 진행하기로 했습니다. 참고로 Ollama 모델들은 개인 맥미니 16GB에서 돌릴 거기 때문에, 크기가 큰 모델은 못 돌려봅니다. 목록은 아래와 같습니다.
- gpt-4o-mini
- claude-3.5-sonnet-20241022 (얘는 꽤 비싸긴 하지만..)
- claude-3.5-haiku-20241022
- llama3.2 (3.2b)
- exaone3.5 (7.8b)
- phi-4 (vanilj/Phi-4, 14.7b)
- korean-yanolja-eeve (lancard/korean-yanolja-eeve, 10.8b)
- linkbricks-llama3.1-korean:8b (benedict/linkbricks-llama3.1-korean:8b)
아래 코드로 모델 initialization 을 처리했습니다.
from langchain_ollama import ChatOllama
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
def initialize_llm(model_name):
ollama_model_map = {
"exaone3.5": "exaone3.5",
"llama3.2": "llama3.2",
"phi-4": "vanilj/Phi-4",
"korean-yanolja-eeve": "lancard/korean-yanolja-eeve",
"qwen2.5": "qwen2.5",
"linkbricks-llama3.1-korean:8b": "benedict/linkbricks-llama3.1-korean:8b",
# "smallthinker": "smallthinker", # 답을 내는데 너무 오래 걸립니다
}
anthropic_model_map = {
"claude-3-5-sonnet-20241022": "claude-3-5-sonnet-20241022",
"claude-3-5-haiku-20241022": "claude-3-5-haiku-20241022",
}
openai_model_map = {
"gpt-4o-mini": "gpt-4o-mini",
}
if model_name in ollama_model_map:
return ChatOllama(model=ollama_model_map[model_name])
elif model_name in anthropic_model_map:
return ChatAnthropic(model=anthropic_model_map[model_name])
elif model_name in openai_model_map:
return ChatOpenAI(model=openai_model_map[model_name])
elif model_name == "deepseek-v3":
return ChatOpenAI(model="deepseek-chat", openai_api_key=os.getenv("DEEPSEEK_API_KEY"), openai_api_base="https://api.deepseek.com", max_tokens=1024)
raise ValueError(f"Model {model_name} not found")Troubleshooting
- 가끔 JSON 형식에 맞지 않는 답변을 주기도 해서, 최대 3번 시도하여 JSON 답변을 주지 않으면 오답으로 처리했습니다.
실행
적당히 commandline interface를 짜고, main 함수를 만들어 아래와 같은 실행 스크립트를 작성합니다.
from langchain_ollama import ChatOllama
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
from collections import defaultdict
from parser import parse_problem, compose_prompt
from tqdm import tqdm
import argparse
import os
import json
import pandas as pd
def initialize_llm(model_name):
ollama_model_map = {
"exaone3.5": "exaone3.5",
"llama3.2": "llama3.2",
"phi-4": "vanilj/Phi-4",
"korean-yanolja-eeve": "lancard/korean-yanolja-eeve",
"qwen2.5": "qwen2.5",
"linkbricks-llama3.1-korean:8b": "benedict/linkbricks-llama3.1-korean:8b",
# "smallthinker": "smallthinker",
}
anthropic_model_map = {
"claude-3-5-sonnet-20241022": "claude-3-5-sonnet-20241022",
"claude-3-5-haiku-20241022": "claude-3-5-haiku-20241022",
}
openai_model_map = {
"gpt-4o-mini": "gpt-4o-mini",
}
if model_name in ollama_model_map:
return ChatOllama(model=ollama_model_map[model_name])
elif model_name in anthropic_model_map:
return ChatAnthropic(model=anthropic_model_map[model_name])
elif model_name in openai_model_map:
return ChatOpenAI(model=openai_model_map[model_name])
elif model_name == "deepseek-v3":
return ChatOpenAI(model="deepseek-chat", openai_api_key=os.getenv("DEEPSEEK_API_KEY"), openai_api_base="https://api.deepseek.com", max_tokens=1024)
raise ValueError(f"Model {model_name} not found")
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, required=True)
parser.add_argument("--year", type=int, default=2024)
parser.add_argument("--subject", type=str, default="eng")
return parser.parse_args()
def main():
args = parse_arguments()
llm = initialize_llm(args.model)
problems = os.listdir(f"problems/{args.year}/{args.subject}")
problem_indices = [int(problem.split(".")[0]) for problem in problems]
df = defaultdict(list)
for problem_idx in tqdm(problem_indices):
problem = parse_problem(args.year, args.subject, problem_idx)
prompt = compose_prompt(args.year, args.subject, problem_idx)
# retry at most three times if the result is not a valid JSON
for _ in range(3):
try:
result = llm.invoke(prompt)
result_json = json.loads(result.content.strip("```json").strip("```"))
if result_json["answer"] == "":
result_json = {
"answer": "",
"reasoning": "",
}
raise json.decoder.JSONDecodeError
break
except json.decoder.JSONDecodeError:
# fill in the result with empty strings
result_json = {
"answer": "",
"reasoning": "",
}
continue
model_answer = int(result_json["answer"]) if result_json["answer"] != "" else None
df["problem"].append(problem_idx)
df["answer"].append(problem["answer"])
df["model_answer"].append(model_answer)
df["model_reasoning"].append(result_json["reasoning"])
df["correct"].append(model_answer == problem["answer"])
df = pd.DataFrame(df)
df.to_csv(f"results/{args.model.replace('/', '-')}_{args.year}_{args.subject}.csv", index=False)
if __name__ == "__main__":
main()이제 아래와 같이 실행하면 results/deepseek-v3_2025_eng.csv 와 같은 형태로 결과 파일이 쌓이게 됩니다. 이제 돌려볼 일만 남았네요!
python run.py --model deepseek-v3 --year 2025 --subject eng결과
대망의 벤치마크 결과입니다. 제시된 점수는 문제 배점을 고려한 점수가 아니라 정답률임을 감안하고 확인해 주세요.
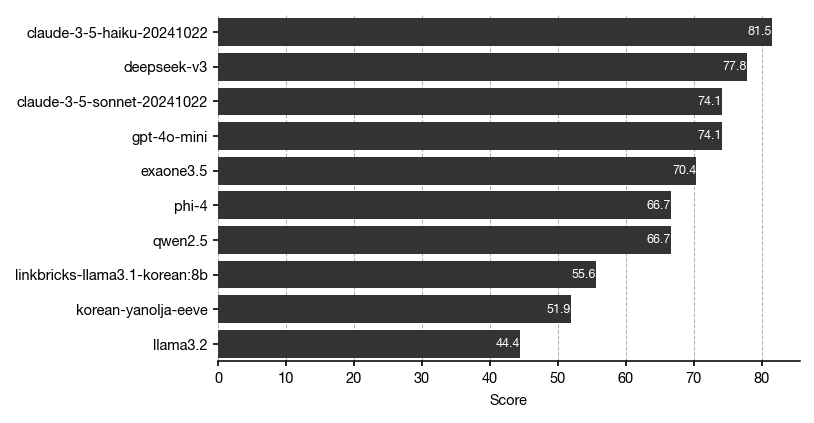
claude-3.5-haiku-20241022가 성능이 제일 좋다는 꽤 의외의 결과를 얻었는데요. 물론 27개의 문제로는 표본이 너무 작아서 그런 것이겠죠?
DeepSeek-V3 모델이 sonnet, 4o-mini를 제친 것도 눈에 띄는군요.
또다른 관찰로는.. 영어 과목에서 전체적으로 평균 90점 정도는 나올 것으로 예상했는데 생각보다 점수가 많이 낮다는 겁니다. 적절한 프롬프트 엔지니어링으로 이 성능들을 더 끌어올릴 수 있을지 궁금해지네요.
한국어 학습 모델 중에서는 exaone3.5 (엑사원 3.5) 7.8b 모델이 가장 좋은 점수를 얻은 것으로 나타났습니다. HyperClovaX 모델도 얼른 추가해봐야겠네요!
앞으로는?
우선 proof-of-concept 실험이 끝났으니, 이제 여기에 살을 붙여 다양한 실험들을 해볼 차례입니다. 이런저런 아이디어들을 정리해 둡니다. 앞으로의 포스팅을 기대해 주세요!
- 더 좋은 모델들 (GPT-4o 등)과 다양한 모델들 (HyperClovaX 포함) 결과를 추가해볼 겁니다.
- 더 큰 오픈소스 모델들을 어떻게 벤치마크에 추가할 수 있을지 고민해봐야겠습니다.
- 문제 파싱 과정을 자동화하여, 역대 모든 수능 문제들을 모으는 식으로 벤치마크를 scale-up 해볼 겁니다.
- 이 벤치마크 프레임워크를 가지고 다양한 프롬프팅 전략을 벤치마크해볼 겁니다.
- 국어, 수학 순으로 벤치마크 과목을 확장해 볼 겁니다.
더보기
 Bongnam Kim
Bongnam Kim


![[Python] trafilatura 라이브러리로 크롤링 쉽게 하기](https://images.unsplash.com/photo-1470334165954-365e14d84faa?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fHBlbGljYW5zJTIwfGVufDB8fHx8MTczNzE4MDg0MXww&ixlib=rb-4.0.3&q=80&w=960)
