인공지능 LLM 모델 수능 성적 비교하기 - 영어 편 (2)
직접 해봤습니다. GPT-4o 부터 Gemini, 신흥 강자 DeepSeek-V3 까지, 2023, 2024, 2025년 3개년도 수능 영어 벤치마크를 수행하여 모델 성능을 비교해 봅니다.

지난 포스팅 인공지능 LLM 모델 수능 성적 비교하기 - 영어 편 (1) 에서는 2025학년도 수능 영어 문제들을 활용하여 간단한 proof-of-concept 벤치마크를 수행해 보았습니다. 가장 기본적인 프롬프트를 활용했고, 비교적 소수의 기본적인 모델만 평가해 보았습니다. 결과는 신기하게도 claude-3.5-haiku의 우승으로 끝났었는데요, claude-3.5-haiku 모델은 적어도 claude-3.5-sonnet에 비해서는 추론 능력이 조금 부족하다고 알려져 있는데 (대신 응답 속도 측면에서 유리함이 있습니다!), 어떻게 haiku가 sonnet을 이길 수 있었는지 의문이었습니다. 수능 영어 task가 우연히 haiku에 더 적합한 task였던 걸까요?
이번 포스팅에서는, 조금 더 풍성한 벤치마크를 해보려고 합니다. 우선 2개년도 수능 데이터를 더 추가해볼 것이고, 평가 모델 또한 OpenAI의 GPT-4o, Google의 Gemini, Upstage의 solar-pro, 네이버의 HyperClovaX 모델 등 쟁쟁한 모델들 또한 참전시켜볼 겁니다.
수능 문제 파싱의 어려움
엄밀한 벤치마크를 위해서는 사용하는 문제 수가 많아야 합니다. 이를 위해, 개발자라면 응당 수능 문제 PDF 파일을 받아서 평가에 사용 가능한 형태인 yaml 파일(지난 포스팅 참조)로 변환하는 로직을 자동화하고 싶은 것은 당연합니다. 저도 이것부터 시도해 보았습니다만, 오히려 이 자동화 로직을 짜는 것이 더 번거롭고, 생각보다 쉽지 않았습니다. 어떤 것들을 시도해 보았고, 어떤 어려움들이 있었는지 기록을 남겨 둡니다.
시도해본 것들
- PyPDF2 등 PDF 파싱 라이브러리를 사용하여 문제 텍스트 추출
- PDF를 markdown으로 변환해주는 툴 사용 (비교적 최신의 markitdown 포함)
 microsoft
microsoft- OCR 활용 (Upstage document OCR 포함)

- llava, llama3.2-vision, Qwen2-VL 등 vision capability가 있는 모델 사용하여 파싱 요청
어려움
- "밑줄 친" 단어들 중 정답을 고르는 문제들이 있는데, 단순 PDF 파싱 및 markdown 변환 툴은 밑줄을 무시해버리는 문제가 있습니다.
- 사람이 보기에는 꽤 파싱이 쉬워 보이는 아래의 선지들이 PDF 파일 구조 때문인지 예쁘게 파싱되지 않는 문제가 있습니다.

- 수능 문제 PDF 파일이 2-column 파일인 바람에, OCR을 활용하여 텍스트로 변환하면 컬럼 구분을 무시하고, 좌우로 인접한 문제들이 합쳐져버리는 문제가 있었습니다. Upstage document OCR 결과로 나오는 bounding box들을 잘 활용해서 같은 column 내의 text만을 이어붙이는 후처리 로직을 짤 수는 있겠지만... 해보지는 않았습니다.
- llava, llama3.2-vision 모델은 한국어 인식 능력이 많이 부족합니다.
- Qwen2-VL 모델은 상대적으로 한국어 인식 능력이 좋지만, "문제를 파싱하여 yaml 파일로 변환하는" task까지는 잘 해결해주지 못하더군요.
우선은 수동으로
이런 어려움들 때문에, 우선은 추가적인 몇개년 정도의 문제는 수동으로 파싱해보기로 했고, 이번 벤치마크에서는 2023학년도, 2024학년도 문제들을 추가했습니다. 저번처럼 듣기평가 문제와 도표 해석 문제는 제외하여 둘 모두 27개씩의 문제, 총 54개의 문제를 추가할 수 있었습니다. 결과적으로는 23, 24, 25학년도 문제를 모두 합쳐 81개의 문제가 되겠네요.
문제 별 배점도 벤치마크에 반영하기로 했습니다. 영어 과목은 2점 혹은 3점의 배점을 가지며, 벤치마크에 참여하는 27개의 문제 총점의 합은 3개년도 모두 61점입니다.
결과는?
23, 24, 25학년도 영어 점수의 평균은 아래와 같이 나타났습니다.
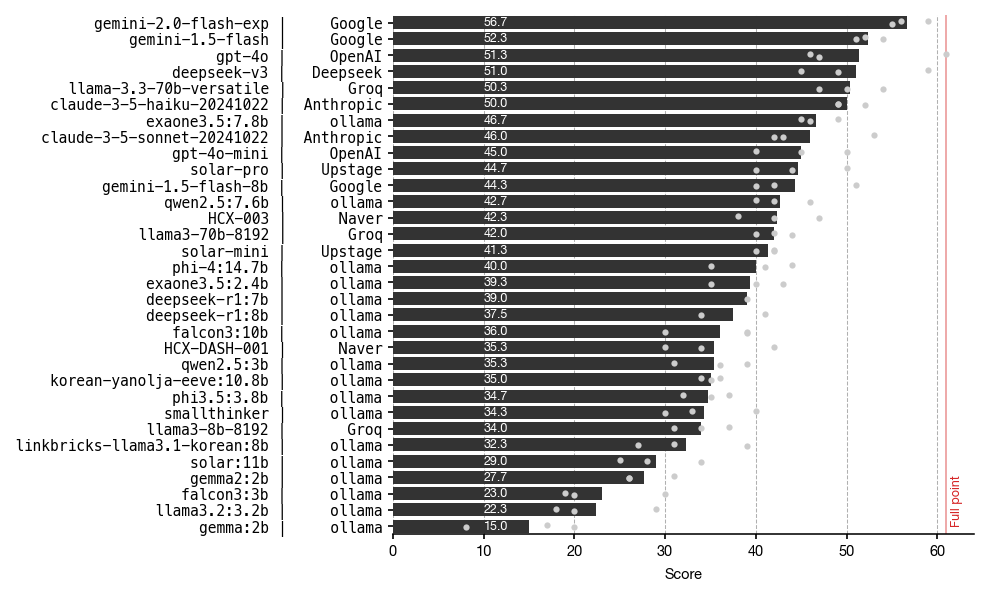
Gemini-2.0-flash-exp 모델이 GPT-4o, Deepseek-v3와 Claude-3.5-sonnet을 누르고 가장 좋은 성능을 보였네요! 🎊그동안 왜인지 모르게, GPT-4o, Claude-3.5-sonnet, Deepseek-v3 과는 달리 Gemini 모델들에는 손이 가지 않는 느낌이었는데, 이 벤치마크 결과를 보니 꽤 쓸만하다는 생각이 들어 앞으로는 종종 사용해야겠다는 생각이 듭니다.
오픈소스 모델 llama3.3 70b의 약진도 눈에 띕니다. 비록 70b로 비교적 큰 모델인 탓에 ollama로 테스트해보지는 못했고, rate limit이 심하게 걸려 있는 (하지만 무료인!) Groq API를 이용하여 테스트해본 결과입니다.
한국에서 학습된 모델 중에서는 LG AI연구원의 EXAONE 3.5가 가장 좋은 성능을 보였습니다. 그 다음으로는 Naver의 HyperCLOVA X (HCX-003 모델), 그리고 Upstage의 solar-pro 모델이 뒤따랐네요. 오픈소스 모델임에도, EXAONE 3.5 모델이 준수한 성능을 보이는 것이 놀랍습니다.
Claude-3.5-sonnet이 JSON output을 제대로 내놓지 못하는 문제
하지만 sonnet보다 haiku가 더 좋은 성능을 내는 것은 여전합니다. 왜 그런지 좀 더 들여다 보겠습니다.
이 벤치마크에서는 편의상 모델이 원하는 JSON output을 내놓지 못하는 경우 오답으로 처리했습니다. 즉, 정답을 맞췄더라도 output formatting을 잘못하여 오답 처리가 된 경우도 있을 수 있다는 거죠. 아래 그림은 JSON formatting 문제가 발생한 개수를 나타냅니다.
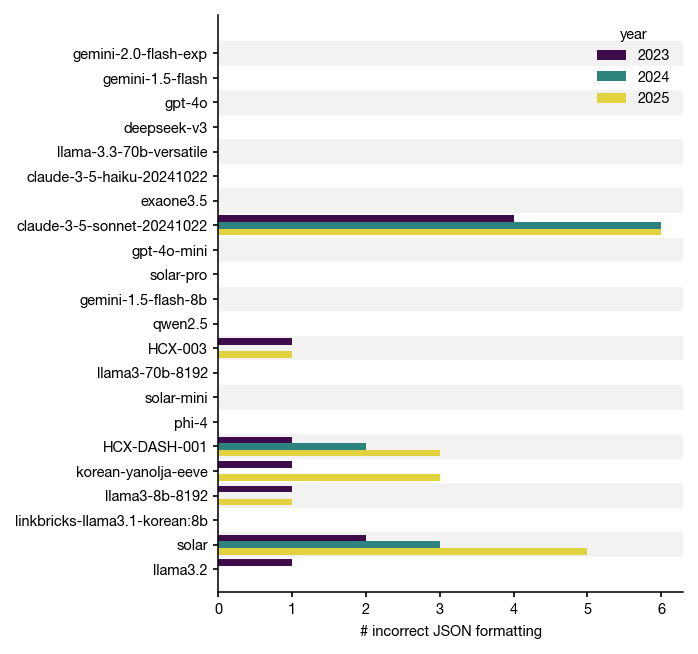
실제로 sonnet에서 꽤 많은 JSON formatting 문제가 발생했었습니다. 그 원인을 들여다보니, 프롬프트 instruction으로 넣어 준 "think step by step" 프롬프트 때문에 모델이 자신의 추론 과정을 함께 출력하기 때문이었습니다 😮
원인을 파악했으니, 이제 프롬프트를 수정하여 sonnet 모델을 다시 평가해봅시다!
<role>
You are a professional problem solver.
</role>
<task>
Given a question and a text, find the answer to the question.
</task>
<instructions>
<instruction>Think step by step.</instruction>
</instructions>
<rules>
<rule>You MUST return the answer in JSON format with two keys: "answer" (integer) and "reasoning" (string)</rule>
<rule>You MUST DISCARD ```json and ``` in the result</rule>
<rule>NEVER include meta-commentary or explanations in the result, just return the JSON</rule>
<rule>The key "answer" must be the index of the choice that is the answer (integer)</rule>
<rule>The key "reasoning" must be a short explanation for the answer (string)</rule>
<rule>NEVER include intermediate steps in the reasoning</rule>
</rules>
<question>
{question}
</question>
<text>
{text}
</text>
<choices>
<choice index="1">{choices[0]}</choice>
<choice index="2">{choices[1]}</choice>
<choice index="3">{choices[2]}</choice>
<choice index="4">{choices[3]}</choice>
<choice index="5">{choices[4]}</choice>
</choices>수정된 프롬프트. Reasoning 과정 intermediate step을 출력하지 않도록 <rule>을 추가했다.
수정된 벤치마크 결과
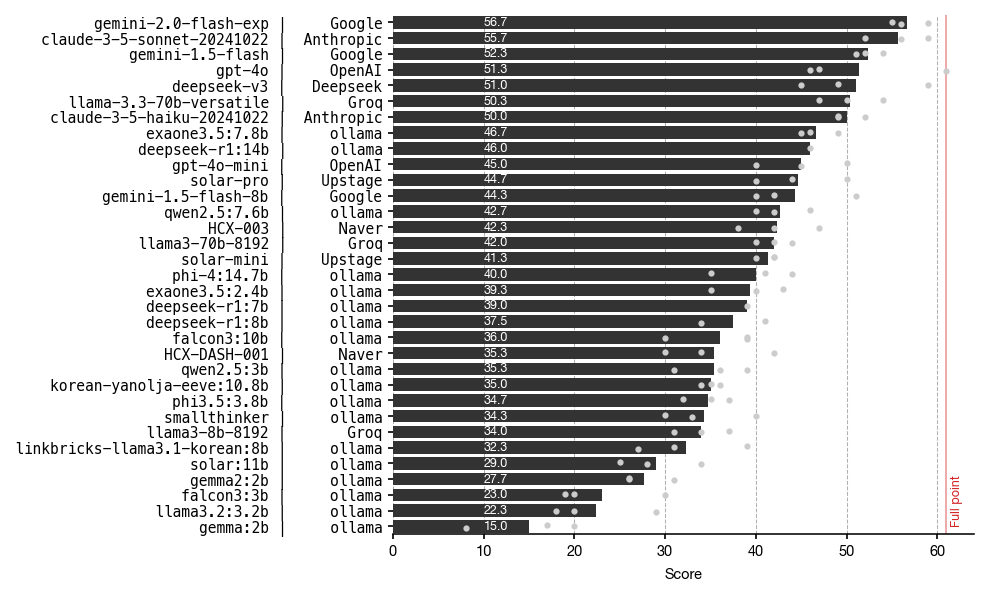
Claude-3.5-sonnet의 문제를 해결하여 측정한 벤치마크 결과는 아래와 같습니다. 기대했던대로 haiku보다는 좋은 성능을 내고 있고, gemini-2.0-flash-exp에 이어 2위를 차지했군요! 🎉
Data leakage에 주의하자
2025학년도 수능 문제는 아마 모든 모델에서 학습 데이터로 사용되지 않았을 테지만, 2023학년도 및 2024학년도 문제는 혹시나 학습 데이터로 사용되어 leakage가 있었을 수도 있습니다. 아래는 모델 별, 연도별 점수 분포를 나타내는 그래프인데, 꽤 많은 모델들이 일관되게 2023학년도보다 2025학년도에 더 좋지 못한 성적을 받고 있는 것을 보면, 이 부분을 의심하지 않을 수 없겠군요.
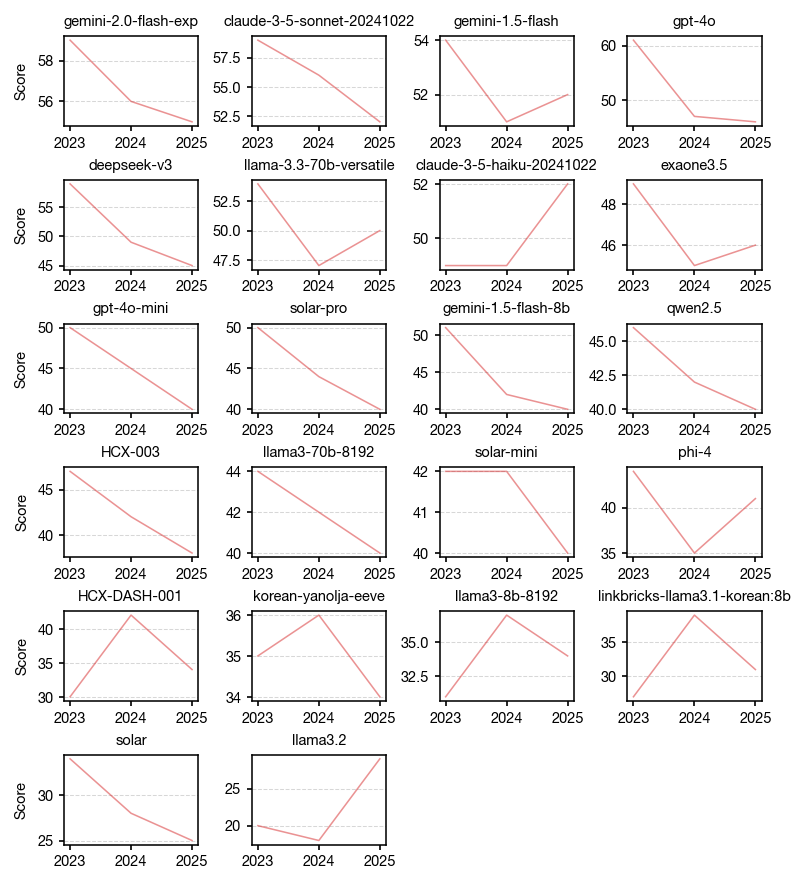
LLM 모델 학습이 어떤 데이터를 사용하여 어떻게 이루어졌는지 모든 모델이 투명하게 공개한다면 학습에 사용된 데이터를 제외하고 벤치마크를 해볼 수 있겠지만, 현실적으로 통제하기는 어려운 부분이라고 생각이 됩니다.
마치며
이제 충분히 다양한 LLM 모델들을 평가하는 프레임워크는 갖춰진 것 같습니다. 짬이 날 때마다 문제 파싱을 하거나, 혹은 문제 파싱 자동화 방법을 조금 더 고민해서 훨씬 더 많은 양의 문제로 벤치마크를 구축하고 싶어집니다 😃
다음 과목으로는, 국어 과목으로 이 모델들을 평가해보고자 합니다. 영어 과목에서는 LLM 3~4대장 (OpenAI, Anthropic, Google + DeepSeek?)의 모델들이 국산 모델에 비해 유의미한 우위를 가져가는 모습인데, 국어 과목에서는 이 경향이 역전될 수 있을지 궁금해지네요. 다음 포스팅도 기대해주세요!


![[Python] trafilatura 라이브러리로 크롤링 쉽게 하기](https://images.unsplash.com/photo-1470334165954-365e14d84faa?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fHBlbGljYW5zJTIwfGVufDB8fHx8MTczNzE4MDg0MXww&ixlib=rb-4.0.3&q=80&w=960)
