[Python] itertools.groupby 설명
종종 요긴하게 사용할 수 있는 파이썬 표준 라이브러리 itertools의 groupby 함수를 간단한 예시와 함께 설명합니다.

파이썬 코딩을 하다 보면 다양한 형태로 List, Set과 같은 iterable한 자료구조에 데이터를 저장하고, 이를 순회하면서 후처리를 하거나 분석 결과를 내놓게 됩니다. 더 나아가서, 종종 이 자료구조 내의 데이터에서 파생된 새로운 iterable을 순회하고 싶을 때도 있습니다. 예를 들어, 리스트의 원소 중 2개씩 골랐을 때 얻을 수 있는 모든 조합을 얻고 싶다거나 (itertools.combinations), 리스트의 원소가 이룰 수 있는 모든 순열 (itertools.permutations)들을 순회한다거나 하는 작업을 해야 할 일이 꽤 있죠.
이 경우에, 파이썬의 표준 라이브러리 itertools를 활용하면 이 작업들을 아주 간단하게 처리할 수 있습니다. 이 포스팅에서는 다른 itertools 함수들에 비해서는 흔히 사용되지는 않지만, 알아두면 요긴하게 사용할 수 있는 itertools.groupby 함수의 작동 방식과 예시를 간단히 설명합니다.
itertools.groupby의 두 파라미터, iterable과 key
itertools.groupby는 최대 두 개의 파라미터를 받습니다.
- 하나는 iterable로서 groupby를 수행하고 싶은 순회 가능한 자료구조이며,
- 다른 하나는 optional 파라미터인 key로서, iterable 내의 각 원소를 "group 구분의 기준이 되는 key 값"에 매핑하는 함수입니다.
itertools.groupby(iterable, key=None)itertools.groupby 작동 방식
itertools.groupby의 작동 방식을 간단히 정리하면 다음과 같습니다.
보다 자세히 설명하면 아래와 같습니다. 다음의 흐름만 따라가면 itertools.groupby의 작동 방식은 쉽게 이해할 수 있을 겁니다.
- iterable의 첫 원소 x1 를 받아서 함수 key에 넣어 나온 key(x1) 값을 k1라고 합니다. (만약 key=None 이면 key(x1) = x1입니다.)
- k에 매핑된 리스트를 관리하는데, 원소 x1를 넣습니다. (k1 -> [x1])
- 다음 원소 x2를 받아서 함수 key에 넣어 나온 key(x2) 값을 k2라고 합니다. 두 가지 경우가 있습니다:
- k2 == k1 인 경우, k1에 매핑된 리스트에 x2를 append합니다.
- k2 != k1 인 경우, k1과 k1에 매핑된 리스트를 (k1, [x1]) 형태로 yield하고, 새로 k2 -> [x2]를 관리합니다.
- 이 과정을 반복합니다.
itertools.groupby 사용 예시
tuple의 리스트가 주어졌을 때, tuple의 특정 값이 같은 원소들을 묶고 싶을 때
아래와 같이 ("chr1", 100, 200)과 같은 형식의 tuple들이 나열된 리스트가 주어졌을 때, tuple 맨 앞의 값이 같은 원소들을 묶어서 리스트로 내놓고 싶은 경우 다음과 같이 하면 됩니다.
import itertools
arr = [("chr1", 100, 200), ("chr1", 200, 300), ("chr2", 100, 200), ("chr2", 300, 400)]
for k, g in itertools.groupby(arr, key=lambda x: x[0]):
print(k, list(g))

연속된 숫자를 한 그룹으로 묶고 싶을 때
약간의 응용이 들어간 사용 예시입니다. 예를 들어, [1, 2, 3, 6, 7, 8, 10, 11, 12]와 같이 하나의 리스트 안에서, (1, 2, 3), (6, 7, 8), (10, 11, 12) 처럼 연속된 수의 그룹들이 등장하여 이 그룹 별로 무언가를 처리하고 싶을 때가 있습니다.
이 '연속된 수의 그룹'이 어떤 공통적인 group key값을 가지게 해야 itertools.groupby를 사용할 수 있는데, 어떻게 하면 될까요? 연속된 수의 그룹들은 1씩 증가하므로, 1씩 증가하는 index를 값과 함께 반환하는 enumerate과 함께 사용하면 될 것 같습니다. 즉, enumerate([1, 2, 3, 6, 7, 8, 10, 11, 12])는 리스트로 변환하면 결국 [(0, 1), (1, 2), (2, 3), (3, 6), (4, 7), (5, 8), (6, 10), (7, 11), (8, 12)]가 되는데, 잘 보면 연속된 수의 그룹들은 숫자값이 할당된 index와 만드는 차이가 똑같습니다. (0-1) = -1, (1-2) = -1, (2-3) = -1 처럼.. 이 성질을 응용합니다.
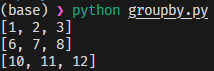
import itertools
arr = [1, 2, 3, 6, 7, 8, 10, 11, 12]
for k, g in itertools.groupby(enumerate(arr), key=lambda x: x[1] - x[0]):
print([x[1] for x in g])
마치며
이번 포스팅에서는 itertools.groupby의 작동 방식과 대표적인 사용 예를 아주 간단히 정리해 보았습니다. 개인적으로 코드 가독성 측면에서는 좋은 방식은 아니어서 적극적으로 사용하기는 어려울 것 같지만, 간단한 분석 작업에서는 알아두면 쏠쏠하게 사용해볼만 할 것 같습니다. 그룹 내에 같은 성질을 가지는 원소들이 있고 그 원소들로부터 공통적인 특성들을 잘만 뽑아낼 수 있다면 말이죠!


![[Python] trafilatura 라이브러리로 크롤링 쉽게 하기](https://images.unsplash.com/photo-1470334165954-365e14d84faa?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fHBlbGljYW5zJTIwfGVufDB8fHx8MTczNzE4MDg0MXww&ixlib=rb-4.0.3&q=80&w=960)
